生物大模型竞品调研
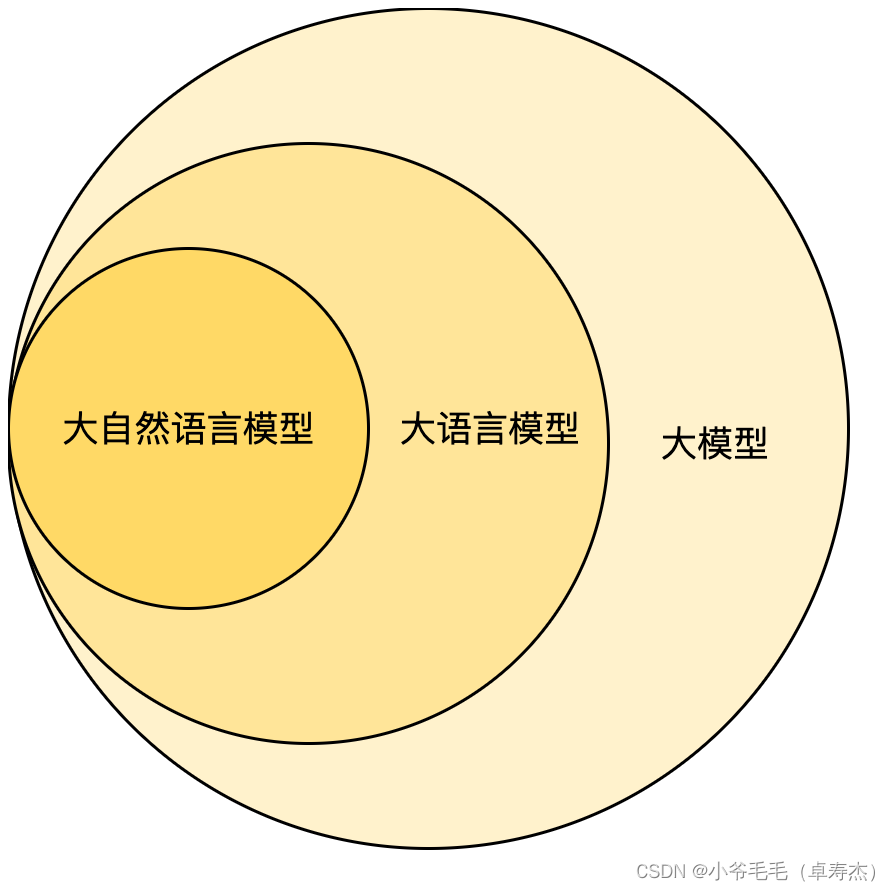
1 概念分类
-
大模型:大模型通常指的是参数量较大、层数较深的机器学习模型,例如深度神经网络。这些模型具有大量的可训练参数,通过在大规模数据集上进行训练,能够更好地捕捉数据中的复杂模式和特征。大模型在各种领域都有广泛应用,包括自然语言处理、计算机视觉、语音识别等。这里的“大”没有明确的界限,0.x B ~ x00 B 参数都可称作大模型。
-
大语言模型:大语言模型是指具有大规模训练参数的语言序列处理模型。这些模型经过大规模的训练,可以理解和生成语言序列。尽管大语言模型主要用于处理自然语言文本,但在某些情况下,它们也可以用于处理非自然语言数据,如编程语言、蛋白质、特定领域的术语等。
-
大自然语言模型:特指目标是模拟人类语言理解和生成的能力的大语言模型。可以应用于多种领域,包括:
-
机器翻译:将一种自然语言翻译成另一种自然语言。
-
文本摘要:从长篇文本中提取关键信息,生成简洁的摘要。
-
问答系统:回答用户提出的问题,基于文本语境提供准确的答案。
-
文本生成:生成文章、故事、对话等自然语言文本。
-
情感分析:分析文本中的情感倾向,如正面、负面、中性等。
-
信息抽取:从文本中提取结构化信息,如实体、关系等。
-
2. 生物-大自然语言模型
结论:工业界和生物相关的大自然语言模型都**偏向医疗行业(用于问诊等),没有生物科学知识(如基因组学等)相关的。**也就是说,类似于定位的生物科学-大自然语言模型,目前工业界是没有的。
| 公司机构 | 时间 | 参数量 | 应用场景 | 亮点 | 参考 |
|---|---|---|---|---|---|
| 微软:BioGPT | 2022.11 | 1.5B(GPT-2) | 可用于辅助生物医学文献的研究、分析和挖掘,包括问答系统、文本生成、信息提取等应用。 | * 相比于基于BERT的模型,BioGPT具备生成能力,可以生成生物医学领域的流畅描述。 * 在六个生物医学自然语言处理任务上表现出色,超过了之前的模型。特别是在BC5CDR、KD-DTI和DDI端到端关系抽取任务上,分别获得了44.98%、38.42%和40.76%的F1得分,以及在PubMedQA任务上获得了78.2%的准确率,创造了新的记录。 | https://github.com/microsoft/BioGPT 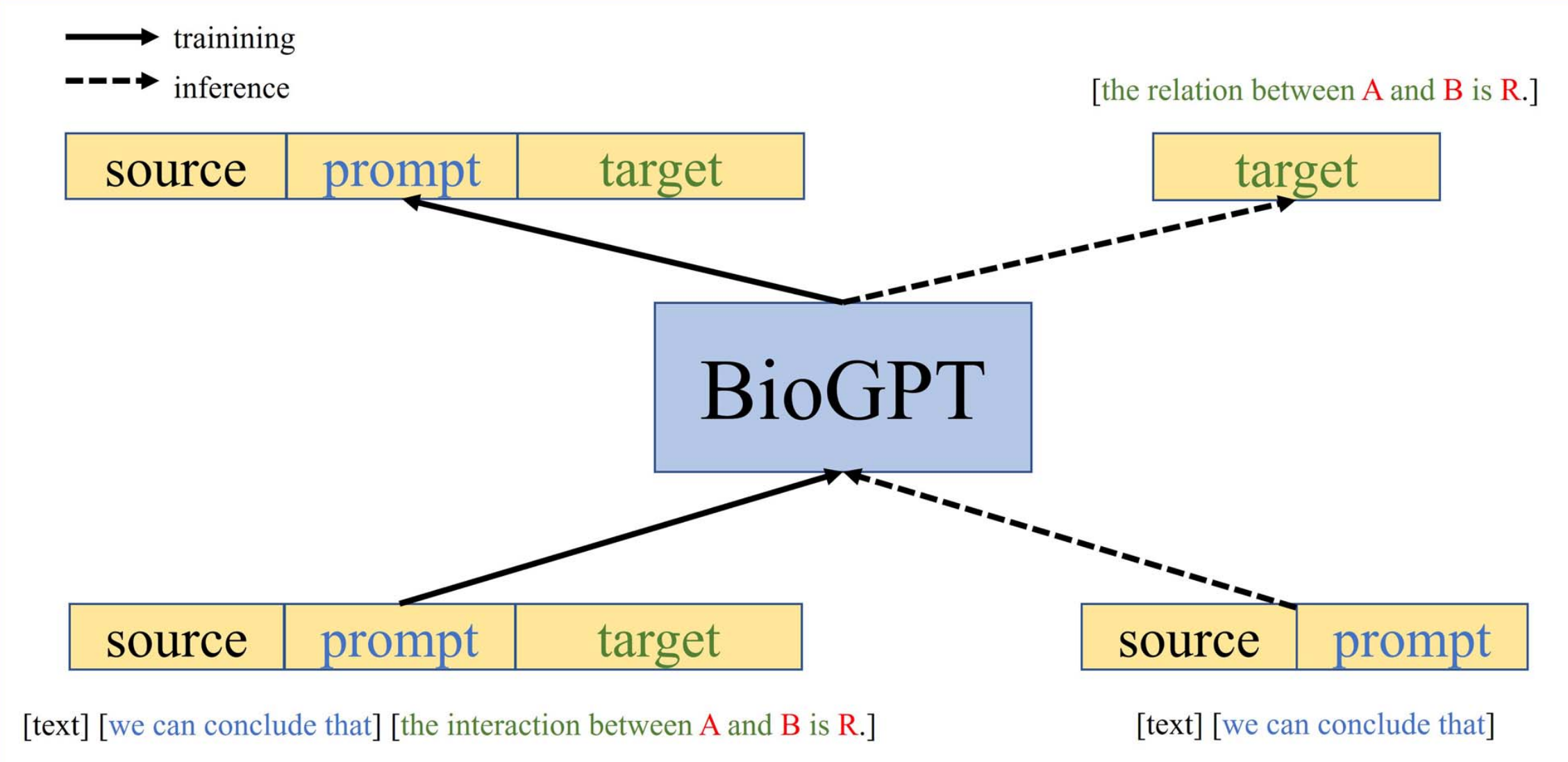 |
| Google、Deepmind:MultiMedQA、Med-PaLM 2 | 2023.3.14 | 540B -> 340B | 为了致力于开发能够检索医学知识、准确回答医学问题并提供推理的 AI 工具 | Med-PaLM 2成为首个在MedQA数据集上以**“专家”级别表现**的LLM,该数据集包含类似于美国医学执照考试(USMLE)的问题,准确率达到85%以上 | 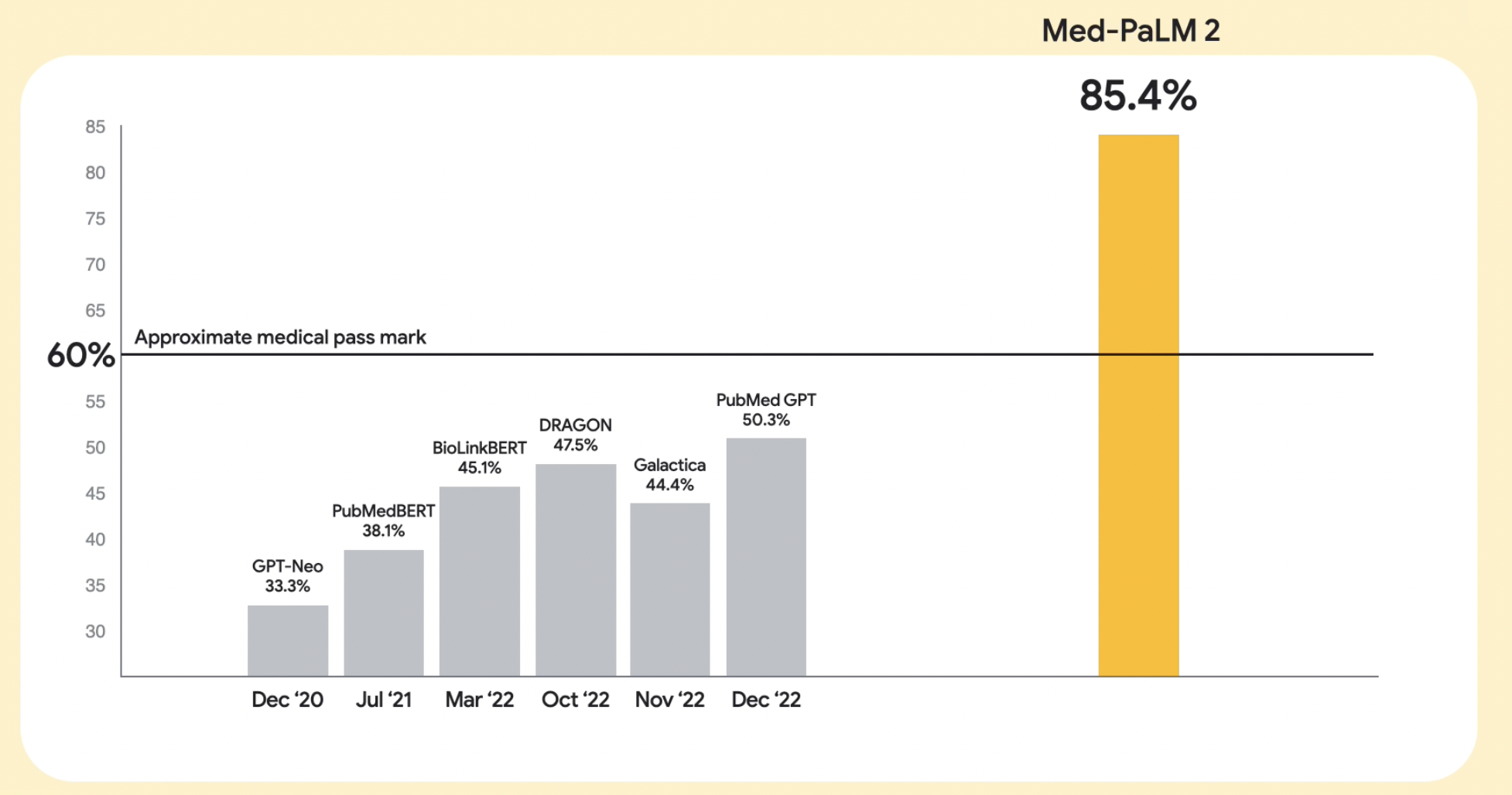 https://sites.research.google/med-palm/ https://sites.research.google/med-palm/ |
| 百度:GBIBot | 2023.3.21 | 260B(文心一言) | 文心大模型首个落地医药行业的应用,医药垂类对话机器人 | 文心大模型与GBI专业数据库的有机结合 | https://news.sina.com.cn/sx/2023-03-23/detail-imymvyyy9637503.shtml |
| 阿里+卫宁健康:WiNGPT | 2023.5 | 6B | 以Colipot方式将互联网问诊等功能融合到WiNEX产品中。通过候诊患者预问诊,人工智能快速记录数据并给出回答,医生可以实时看到和引用AI生成的内容,提升回答效率。 | WiNGPT训练的数据量已达到9720项药品知识、7200余项疾病知识、2800余项检查检验知识、1100余份指南文档,总训练Token数达37亿。共包含7大类基础任务与20多项子任务,在与ChatGPT问诊对比中,WiNGPT更为专业、准确、简练地生成主诉、现病史、诊断和建议。 | 智慧医疗云:https://developer.aliyun.com/article/997643  https://m.21jingji.com/article/20230531/herald/fd29fac5ef48e4700fcb9ebc16c7cba1.html https://m.21jingji.com/article/20230531/herald/fd29fac5ef48e4700fcb9ebc16c7cba1.html |
3. 生物-大语言模型
结论:工业界和生物相关的大语言模型会更集中在蛋白质语言(序列)、氨基酸预测上。
| 公司机构 | 时间 | 参数量 | 应用场景 | 亮点 | 参考 |
|---|---|---|---|---|---|
| 百度&百图生科:HelixFold-Single | 2022.7.28 | 1B | 基于语言模型的单序列的蛋白结构预测模型 | 在CASP14和CAMEO数据集上取得了与基于MSA(多序列比对)的方法相竞争的准确性。所需时间远少于主流蛋白质结构预测流程,展示了它在需要进行多次预测的任务中的潜力。 | 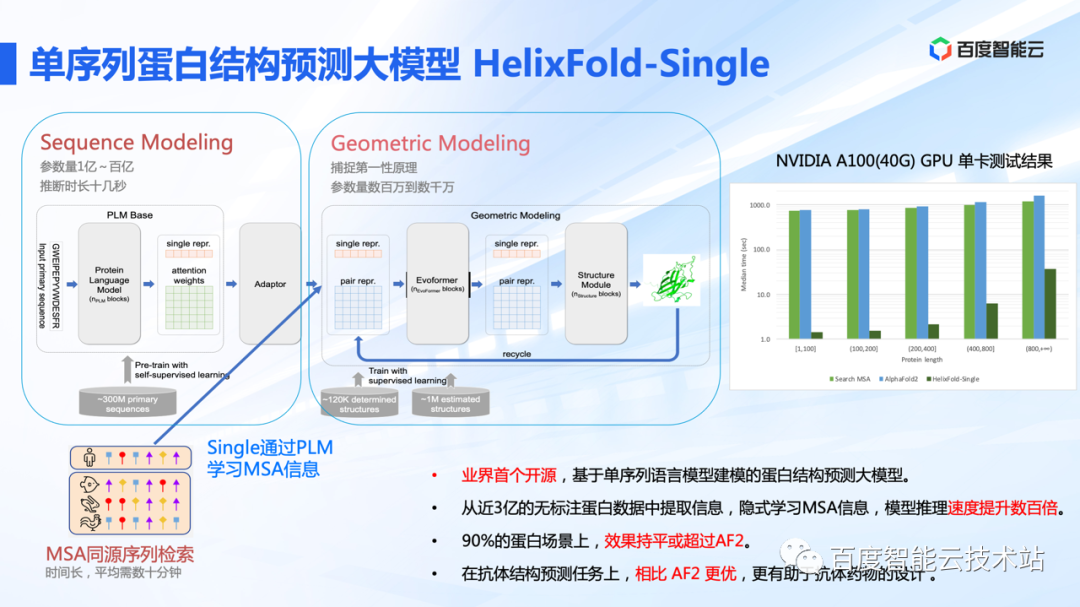 https://arxiv.org/pdf/2207.13921.pdf https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold-single https://arxiv.org/pdf/2207.13921.pdf https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold-single |
| NVIDIA:BioNeMo | 2022.9.20 | 1B | 大型生物分子语言模型,帮助科学家更好地了解疾病,并为患者找到治疗方法。该LLM框架将支持化学、蛋白质、DNA 和 RNA 数据格式。 | BioNeMo 是 NVIDIA NeMo Megatron 框架的扩展,可实现大规模自监督语言模型的 GPU 加速训练。这一针对特定领域的框架支持以 SMILES 化学结构标记表征的分子数据、以及以 FASTA 氨基酸和核酸序列字符串表征的分子数据。 | https://www.youtube.com/watch?v=PWcNlRI00jo&t=4399s |
| 腾讯:scBERT | 2022.9.27 | 110~340M | 能给细胞中的每个基因都印上专属“身份证”,可用于临床单细胞测序数据,并辅助医生描述准确的肿瘤微环境、检测出微量癌细胞,从而实现个性化治疗方案或者癌症早筛。同时,对疾病致病机制分析、耐药性、药物靶点发现、预后分析、免疫疗法设计等领域都具有极其重要的作用。 | 首次将transformer运用到单细胞转录组测序数据分析领域。该模型基于BERT范式,将细胞中基因的表达信息转化成可被计算机理解、学习的语言,并对细胞进行精准标注。通过了9个独立数据集、超过50万个细胞、覆盖17种主要人体器官和主流测序技术组成的大规模benchmarking测试数据集上,该算法模型的优越性均得以验证。其中,在极具挑战的外周血细胞亚型细分任务上,相较现有最优方法的70%准确度提升了7%。 | 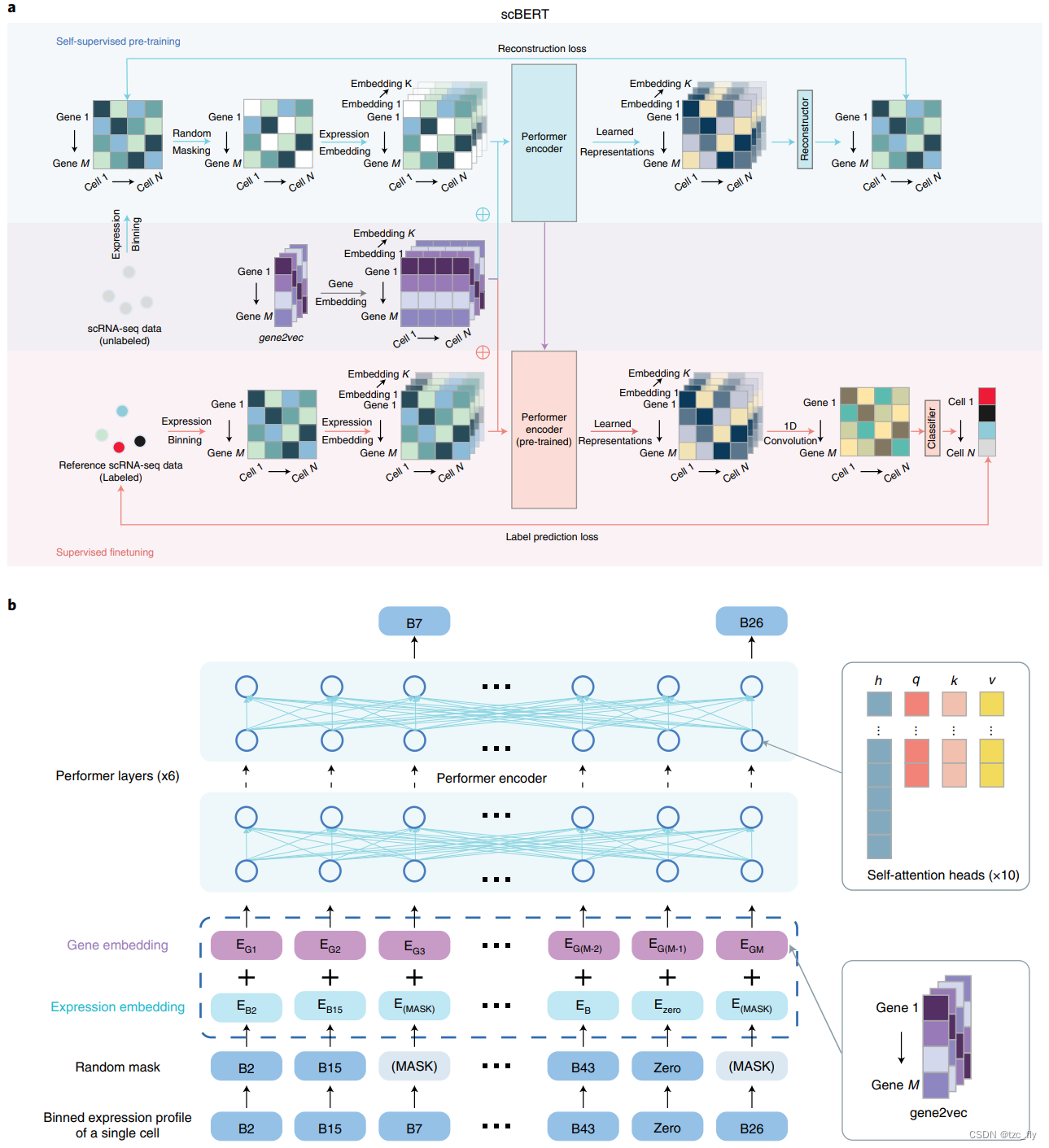 https://github.com/TencentAILabHealthcare/scBERT https://github.com/TencentAILabHealthcare/scBERT |
| Meta:ESM2 | 2022.12.22 | 15B | 由于语言模型的迷惑性和结构预测的准确性之间有很强的联系,当ESM-2能较好地理解蛋白质序列,驱动ESMFold获得了准确的原子分辨率结构预测。 | 共评估了228个生成的蛋白质的实验结果,在尺寸排除色谱法中以较高的总成功率(67%)生成可溶性和单体物种。 推理时间还比AlphaFold2快了一个数量级,将使绘制大型元基因组学序列数据库的结构空间成为可能,有利于发现对天然蛋白质的广度和多样性的新认识,并能发现全新的蛋白质结构和蛋白质功能。 | 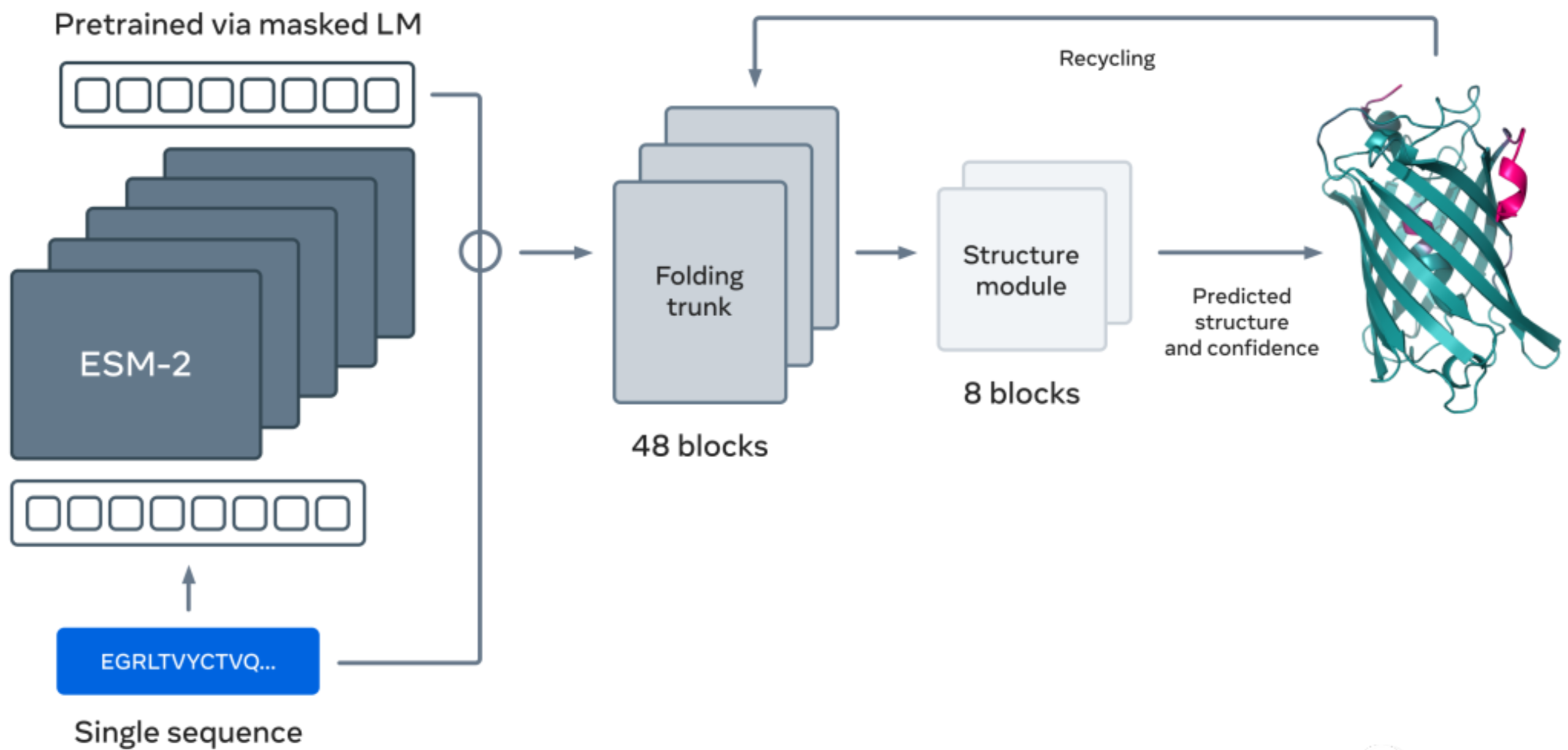 https://www.biorxiv.org/content/10.1101/2022.12.21.521521v1.full.pdf https://www.biorxiv.org/content/10.1101/2022.12.21.521521v1.full.pdf |
| Salesforce:ProGen | 2023.1.26 | 1.2B | 通过学习在给定原始序列中过去的氨基酸的情况下,预测下一个氨基酸的概率来迭代优化,没有明确的结构信息或成对协同进化假设。可以提示从头开始为任何蛋白质家族生成全长蛋白质序列,与天然蛋白质具有不同程度的相似性。 | 在 100 种天然蛋白质的阳性对照集中,72% 的表达良好。ProGen 生成的蛋白质在所有序列同一性箱中与任何已知的天然蛋白质的表达同样好。 | 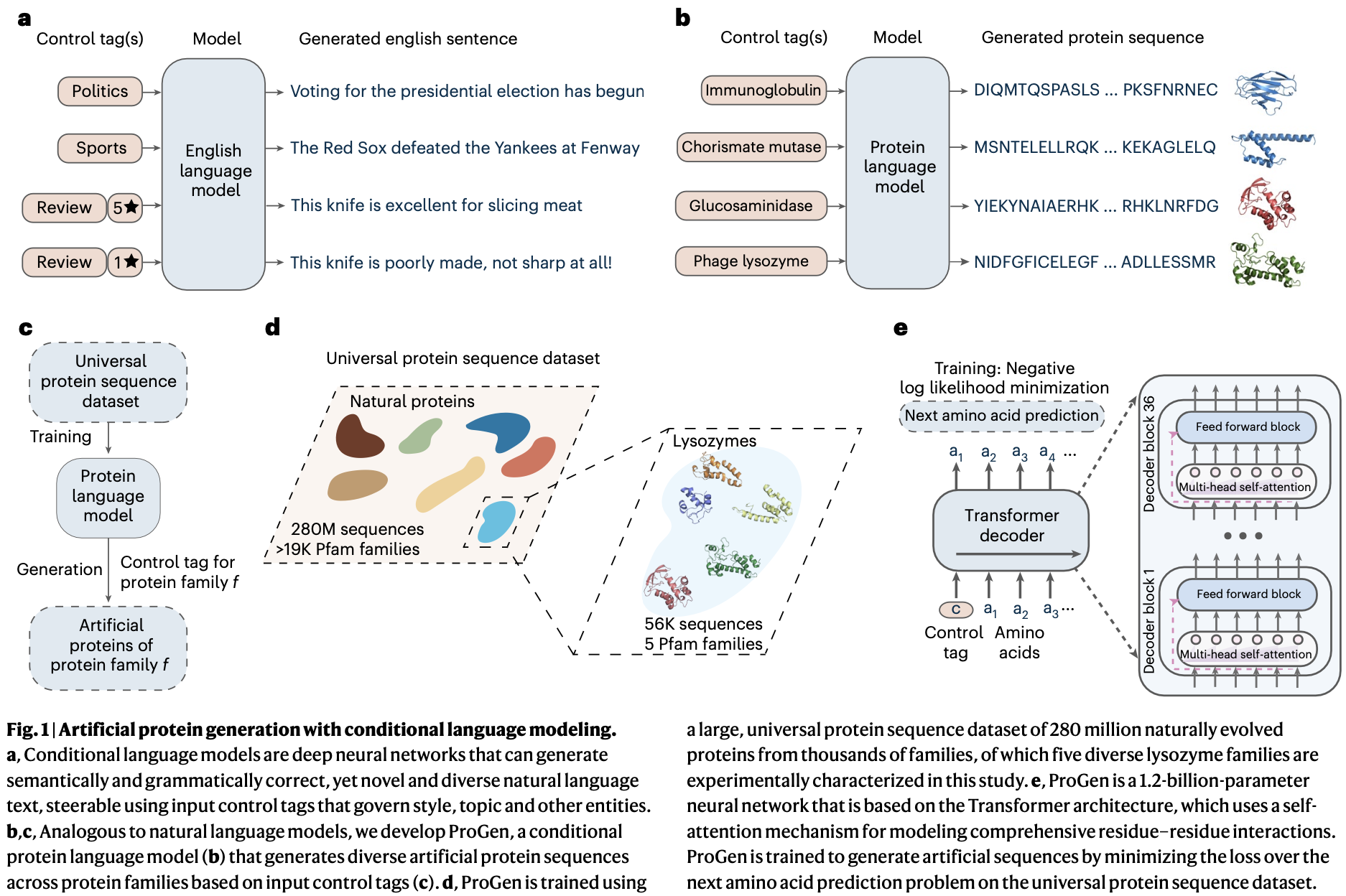 https://www.nature.com/articles/s41587-022-01618-2 https://www.nature.com/articles/s41587-022-01618-2 |
4. 生物-大模型
结论:工业界在,生物大模型相关的布局产品形态多以**“AI平台”的形式向外提供能力,平台包含多个不同任务的大模型,多应用于生物制药**领域。
| 公司机构 | 时间 | 参数量 | 应用场景 | 亮点 | 参考 |
|---|---|---|---|---|---|
| 华为:鹏程.神农 平台 | 2021.9.25 | 未知 | “鹏程.神农”是一个面向生物医学领域的人工智能平台,包含蛋白质结构预测、小分子生成、靶点与小分子相互作用预测以及新抗菌多肽设计与效果评价等模块。制药企业和医学研究机构可以使用“鹏程.神农”提供的AI能力,加速新型药物的筛选和创制。 | https://www.mindspore.cn/largeModel/shennong | |
| 百度&百度生科:BioMap平台 | 2022.2 | 未知 | HelixGEM:化合物表征大模型,自动推断化合物的构象信息,进行化合物属性预测 | HelixGEM-1 使用 2000 万数据进行训练,是业内首个融合化合物三维几何空间构象信息的神经网络,进行自监督学习的工作。HelixGEM1 在 14 个药物属性相关的 benchmarks 都达到业界最优。 | 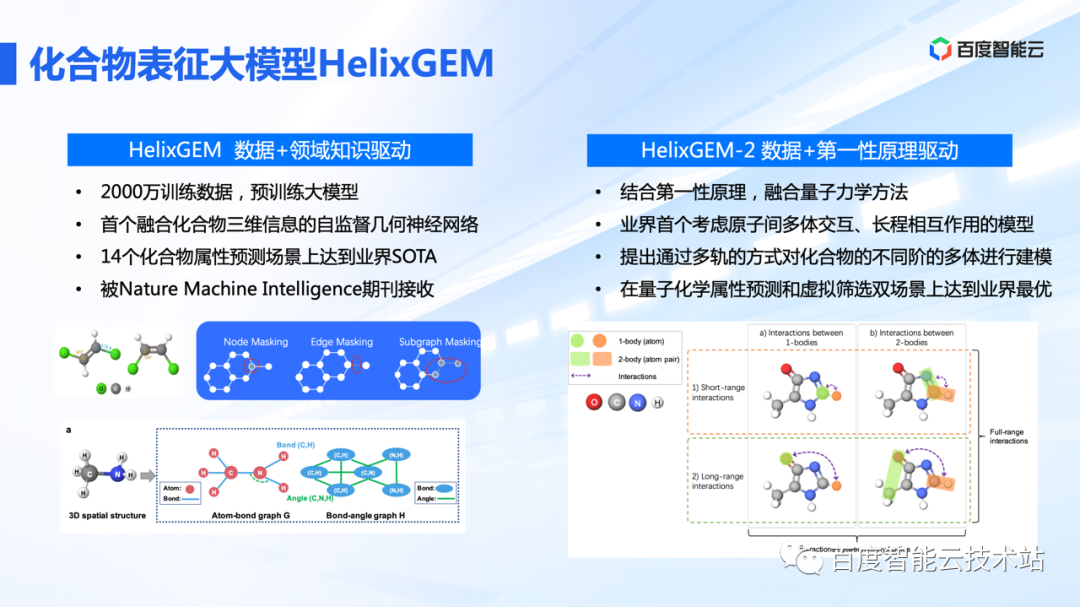 https://zhuanlan.zhihu.com/p/618509086 https://www.biomap.com/zh/ https://zhuanlan.zhihu.com/p/618509086 https://www.biomap.com/zh/ |
| 2022.5 | 未知 | HelixADMET:基于 HelixGEM-1,通过多任务学习、学习指标任务之间的相关性,百度进一步提出一种融合多种任务的知识迁移框架。通过训练任务的先后顺序来控制模型的注意力重点,形成了成药性预测的工作。 | 在同样的预测目标上,HelixADMET 平均领先其他方法 4% 以上。 |  |