日志
undo-log回滚日志:
-
存储:
InnoDB默认将undo-log日志存储在xx.ibdata共享表数据文件中(Mysql5.5版本后支持单独存放),采用段形式存储;在xx.ibdata共享表数据文件中,有一块名为Rollback segment回滚段的区域,每个回滚段中有1024个undo-log segment,每个undo段可以存储一条旧数据,执行写操作时,undo-log就是写入到这些段中,且在MySQL5.5版本后默认存在128个回滚段,即支持128*1024条undo记录存在,但其是动态管理的,若超出128*1024则会额外创建回滚段; -
内容:存储的是旧数据;
-
流程:当一个事物执行写操作修改某行记录时,首先会将旧数据拷贝到
xx.ibdata文件中,将行记录的隐藏字段roll_prt指向xx.ibdata文件中的旧数据,然后再更改表上数据; -
作用:
- 回滚事物;
- 生成版本链实现MVCC;
-
缓冲区:在写入
undo-log时,并不会之间去往磁盘中的xx.ibdata文件写数据,而是先写入undo_log_buffer缓冲区中,之后再由后台线程去刷写磁盘; -
数据清理:由
purger线程负责,其内部会维护一个ReadView,它会以此为判断依据,来决定何时移除undo记录; -
相关参数:
-
innodb_max_undo_log_size:本地磁盘文件中,Undo-log的存储最大值,默认1GB; -
innodb_rollback_segments:每个链接回滚段数量,默认1个;MySQL5.6: -
innodb_undo_logs:每个链接回滚段数量,Mysql5.6默认128个; -
innodb_undo_directory:undo-log存放目录,默认.ibdata; -
innodb_undo_directory:是否开启undo-log的在线压缩功能,即日志文件超过大小一般时自动压缩,默认OFF关闭; -
innodb_undo_tablespaces:指定undo-log分成几个文件来存储,必须开启innodb_undo_directory;
-
redo-log重做日志:
-
内容:记录了事务对数据库所做的修改操作,就是对某个表空间的某个数据页的某个偏移量的地方修改了几个字节的值,它需要记录的其实就是表空间号+数据页号+偏移量+修改的长度+具体的值等信息;
-
作用:
InnoDB为了提升Mysql整体的读写性能,在内存中创建了一个BufferPool缓冲池,所以在运行过程中大量操作会汇集在内存中运行,在执行写操作时,会先将数据写入到缓冲池中,之后由后台线程再刷写到磁盘中,这也导致若数据写入内存但还没刷入磁盘时,mysql突然宕机了,就会丢失部分数据,Redo-log日志就是为了解决这种问题; -
流程:
Redo-log是一种预写式日志,即在向内存写入数据前,会先写日志,当后续数据未被刷写到磁盘、Mysql宕机时,可以通过日志来恢复数据,确保所有提交的事物都会被持久化; -
redo-log刷盘策略:redo-log也会先写在内存在redo_log_buffer缓冲区中;既然是先写内存再写磁盘,就可能丢失数据,是否会掉失数据,这就跟它的刷盘策略有关了;- 刷盘策略
innodb_flush_log_at_trx_commit参数控制:0:每隔一秒刷写一次;Mysql宕机可能会丢失一秒数据;1:每次事物提交刷写一次;性能最差、最安全、默认策略;系统宕机也可能存在数据丢失;2:事物提交后,将记录放到内核缓冲区,由操作系统控制刷盘;性能最佳;
- 默认是每次事物提交刷写一次,这样做的好处是:
- 日志比数据先落磁盘,所以就算Msql崩溃也可以通过日志恢复;
- 写日志是以追加的形式写到末尾,是顺序写入;而写入表数据时,需要去计算数据位置,是随机写入;
-
相关参数:
innodb_flush_log_at_trx_commit:设置redo_log_buffer的刷盘策略;innodb_log_buffer_size:指定redo_log_buffer的缓冲区大小,默认为16MBinnodb_log_group_home_dir:指定redo日志文件存储路径,默认为./;innodb_log_files_in_group:指定redo日志的磁盘文件数量,默认为2个;innodb_log_file_size:指定redo日志每个磁盘文件的大小限制默认为48MB;innodb_log_compressed_pages:是否对redo-log日志开启页压缩机制,默认ON,与InnoDB的压缩机制有关;innodb_log_checksums:redo-log日志的完整性校验机制,默认开启;不开启可能会出现刷写数据时,只刷一半的情况;innodb_log_write_ahead_size:设置checkpoint刷盘机制每次落盘动作的大小,默认为8K,必须要为4k的整数倍,这跟read-on-write问题有关,具体的可以参考;
-
redo-log日志文件组:以两个文件为例;
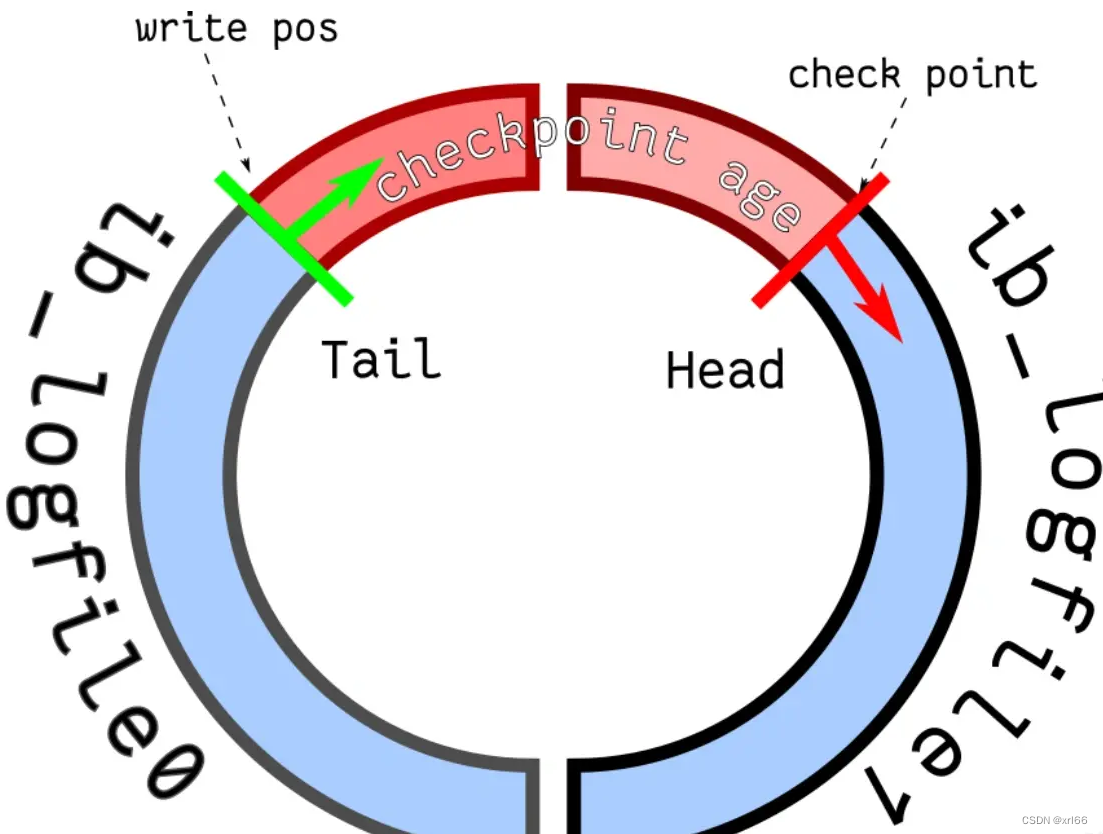
-
两个指针:
write pos:记录文件写到哪个位置;check point:表示目前哪些记录已失效且可以被擦除(覆盖);
-
两个区域:
- 图中红死区域:表示写入日志记录的可用区域;
- 图中蓝色区域:表示日志落盘但数据还未落盘的记录;
-
流程:当一个事物写了
redo-log日志后write pos指针会向前移动,红色区域减少;当一个事物所写数据的写入了本地磁盘后,check point会向前移动,蓝色区域减少;当write pos指针追上check point指针时,红色区域消失,代表着redo-log日志满了,此时当mysql执行写操作会被阻塞,所以会触发checkpoint刷盘机制,将未落盘的数据写入磁盘,增加redo-log的可用区域,阻塞的写事物才能继续执行; -
redo-log两阶段事物提交:- 解决问题:
bin-log和redo-log日志数据可能不一致,从而导致主从同步时的数据不一致;- 先写
bin-log再写redo-log:先写bin-log成功,然后再写redo-log时突然宕机了,重启后redo-log没有记录该事物,则不会恢复该事物数据,但bin-log中记录这个事物数据并同步到从机上,从而导致主机和从机数据不一致; - 先写
redo-log再写bin-log:先写redo-log也同理,会导致bin-log中数据少一条,从而导致主机和从机数据不一致;
- 先写
- 两阶段提交流程:
redo-log(prepare):写入redo-log(prepare)日志,状态为准备状态;若此时宕机,事物还未提交,不会导致数据变更;bin-log:写入bin-log日志;若此时宕机,重启后会根据前面记录的redo-log日志记录中的事物ID,回滚前面写入的数据;redo-log(commit):写入redo-log(commit)日志,状态为完成状态;此时崩溃,因为bin-log已经写入成功,所以重启后会再次提交事物,写入redo(commit)记录;- 实际就是在故障恢复时,会根据
redo-log(prepare)准备状态的记录的事物ID,来判断bin-log中是否有这个事物ID的记录数据,若有则重新提交事物,若没有则回滚之前的写入;
- 解决问题:
-
bin-log二进制日志:-
内容:记录所有对数据库表结构变更改和表数据修改的操作,不记录
select、show这类的读操作,以二进制的形式存储; -
作用:数据灾备、同步;
-
缓冲区:与前面两个日志的缓冲区位与
InnoDB的BufferPool中不同,bin-log的缓冲区bin_log_buffer位于每条线程中;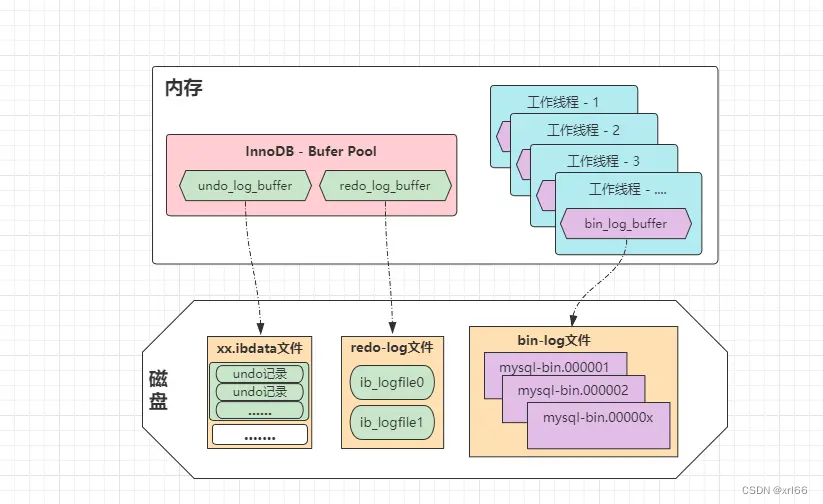
bin_log_buffer放在工作现场的原因:兼容引擎,且不存在并发问题;
-
相关参数:
sync_binlog:刷盘策略;0: 每次事物提交时,将日志放入内核缓冲区,由操作系统控制刷写时机;1: 每次事物提交时,刷入磁盘`;
log_bin:是否开启bin-log日志,默认ON开启;log_bin_basename:设置bin-log日志的存储目录和文件名前缀,默认为./bin.0000x;log_bin_index:设置bin-log索引文件的存储位置;因为本地有多个日志文件,需要用索引来确定目前该操作的日志文件;binlog_format:指定bin-log日志记录的存储方式,可选Statment、Row、Mixed;max_binlog_size:设置bin-log本地单个文件的最大限制,最大只能调整到1GB;binlog_cache_size:设置为每条线程的工作内存,分配多大的bin-log缓冲区;binlog_do_db:设置后,只会收集指定库的bin-log日志,默认所有库都会记录。- …
-
文件存储和格式:
- 采用追加写的形式,一直向末尾写入新的数据,当一个日志文件写满后会创建一个新的文件,文件命名为
mysql-bin.000001、mysql-bin.000002...,可通过show binary logs;命令查看已有的bin-log日志文件; - 存储的日志记录有三种格式:
statment:每条会对数据库产生变更的sql都会记录到bin-log中,如update test ser name='1m' where id = 1;,还会记录sql的上下文信息(执行时间、事物ID、日志量等);- 优势:日志量少,恢复数据较快,做主备等高可用架构时,数据同步也会较小;
- 缺点:可能出现数据不一致的情况,如sql中使用了
sysdate()、now()等这类函数;sysdate()取的是当前机器时间,当主从架构做数据同步时,若主机和从机的时间不同步,就会导致主机和从机上的数据不一致;
row:记录具体哪一个分区中的、哪一页中的、哪一行数据被修改了; 如update test ser name='1m' where id = 1;记录的不是这句sql而是ID=1这条数据,会将其更改后的值记录到bin-log日志中;- 优势:不会出现数据不一致的情况;
- 缺点:数据量大,磁盘IO和网络带宽开销会很高;
mixed:混合模式,即statment、row的结合版,对于可以复制的sql采用statment记录,不能复制的采用row记录;
- 采用追加写的形式,一直向末尾写入新的数据,当一个日志文件写满后会创建一个新的文件,文件命名为
-
与
redo-log的区别:- 生效范围不同:
redo-log是InnoDB独有的,bin-log是所有引擎通用的; - 写入方式不同:
redo-log是循环写入,bin-log是创建新文件追加写入; - 文件格式不同:
redo-log记录的都是变更后的数据,bin-log会记录sql语句; - 使用场景不同:
redo-log主要用于故障情况下的数据恢复,bin-log用于数据灾备、同步;
- 生效范围不同:
-
查看方式:通过Mysql提供的
mysqlbinlog工具解析查看;
-
error-log错误日志:
- 内容:记录
Mysql-service的启动、停止时间,以及报错的诊断信息,也包括了错误、告警、提示等多个级别的日志详情; - 作用:可以用来监控Mysql的运行状态,便于预放故障、发现故障;也辅助Mysql由于非外在因素(断点、硬件损坏…)导致崩溃时的问题排查和故障修复;
- 存储:默认存储在mysql安装目录下的data文件夹中,也可以通过
SHOW VARIABLES LIKE 'log_error';命令来查看; - 参数:
log-erroe:指定存储位置;
slow-log慢查询日志:
- 内容:耗时sql;当一条sql的执行时间超过规定阀值时,就会记录到慢查询日志中;
- 作用:可以辅助排查系统性能问题;
- 参数:
slow_query_log:设置是否开启慢查询日志,默认off关闭;slow_query_log_file:指定存储目录;long_query_time:慢sql阀值,默认10s,可以通过set global long_query_time = 1;设置;
general-log查询日志:
- 内容:mysql收到的所有查询命令,如
select、show等,无论sql语法正确还是错误,执行正确还是错误都会记录; - 作用:可辅助定义慢sql日志的
long_query_time参数; - 参数:
general_log:是否开启查询日志,默认off关闭;general_log_file:指定查询日志的存储路径,默认在库的目录下,主机名+.log;
relay-log中继日志:
- 内容:从主机同步过来的
bin-log数据; - 作用:主从同步数据的“中转站”;
- 存储:与
bin-log类似,存在xx-relaybin.index索引文件,以及多个数据文件xx-relaybin.00001、xx-relaybin.00002....;






![练习 13 Web [极客大挑战 2019]Secret File](https://img-blog.csdnimg.cn/direct/fb3ba218624c4aadafa31f1e08323319.png)