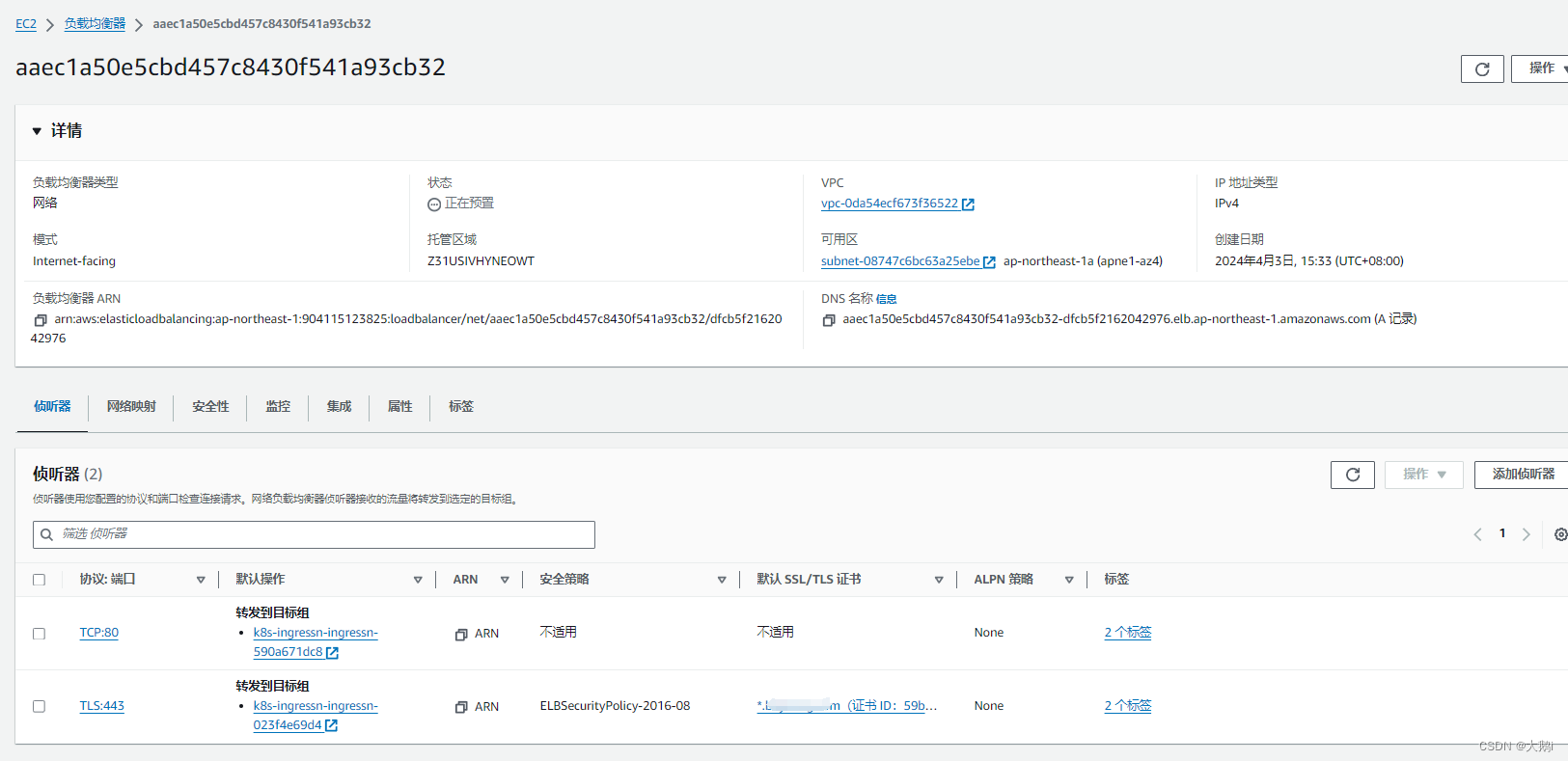
目录
R对象的基本类型
R对象的属性
R的数据结构
向量
矩阵
数组
列表
因子
缺失值NA
数据框
R的数据结构总结
R语言可以进行探索性数据分析,统计推断,回归分析,机器学习,数据产品开发
R对象的基本类型
R语言对象有五种基本类型,分别是字符,数值,整数,复数,逻辑
你可能有疑问,整数也好,复数也好,不都是数值吗?为什么要分成好几种类型呢?可以看这个例子

class函数用来查看某个变量的类型,同样的一个数3.14.如果不加L,就是数值型,加上L就是整数型,这个了解即可
R对象的属性
前面介绍的类型是R对象的某一种属性,除了类型之外,R还有名称,维度(比如矩阵或者数据框的几行几列),长度等等属性。
R的数据结构
向量
向量用于存放一组类型相同的数据,有点像C语言中的数组
向量的创建可以使用vector函数
![]()
这样就创建了一个向量,长度是十个字符,内容均为空字符,因为我们在前面创建的时候没有初始化

也有更便捷的创建方式如
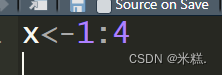
这样就生成了一个1到4的向量

这种方式虽然便捷,但是只能创建等差的数据
创建向量还可以使用c函数,比如

这样就创建了这样一个向量

使用c函数创建向量的好处在于可以随意地输入我们想要的内容
可以看见使用c函数和直接1:4创建的向量一个是数值型一个是整数型,不比在意这个差异,这个差异并不会造成什么影响。
我们说向量只能用来存放一组相同类型的数据,因此我们在用c函数创建向量的时候如果给了不同类型的数据,比如
![]()
那么R其实并不会直接报错,而是会自动把他们强制转换成相同类型的元素

可以看到这里R就自动把我们输入的三个不同类型的数据都转换成了字符类型。这种转换是隐式的。不需要我们再单独用指令去完成。实际上R语言中也有单独的强制类型转换的函数,就是as.某类型,比如
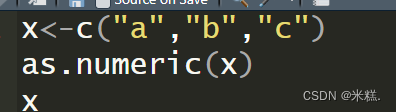
运行结果如图
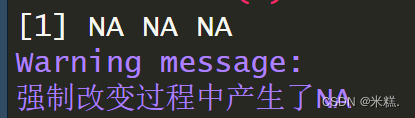
这是因为R不知道如何把a,b,c三个字符转换成数值型,因此使用了缺失值NA来填充
R的属性还有名称,因此我们可以给创建的向量中每个元素起一个名字,使用的是names函数,比如

运行结果如图
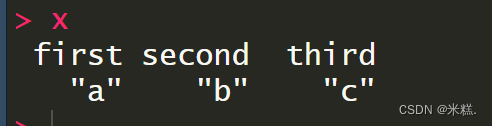
这代表前三个元素的名字分别为first,second,third
矩阵
矩阵有两个维度,即行和列,矩阵中的元素必须是相同类型的元素
矩阵也可以存放多个元素,实际上可以把矩阵当做一个向量+维度
创建矩阵可以使用函数matrix,matrix函数至少需要两个参数即nrow和ncol,分别代表行数和列数,比如

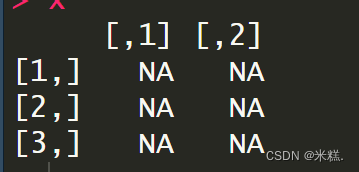
这样就创建了一个三行两列的元素,由于我们并没有在创建的时候对矩阵内容进行初始化,因此矩阵内容均以缺失值填充,如图
我们当然也可以在创建的同时对矩阵进行赋值,比如

这样就把矩阵内容初始化成了1到6,默认是竖着初始化的

查看矩阵的维度(其实就是行和列)可以使用函数dim,如图
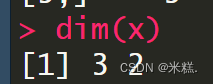
这个函数在查看巨大的矩阵时非常的方便。
我们前面提到过矩阵其实就是向量+维度,根据这个思路,我们只需要给某个向量一个维度信息,就构成了一个矩阵,比如

y是一个向量,dim(y)表示y的维度信息,我们主动给这个维度信息赋值为3和2,表示y有三行两列,运行之后结果如图

一个三行两列的矩阵就创建完成了,内容填充使用的是向量y的内容
合并两个矩阵的方法
合并两个矩阵就要考虑是按行进行合并还是按列进行合并
比如现在要把图中的y和z两个矩阵拼接起来

如果是按行拼接,就是这样

如果是按列拼接,就是这样

前面介绍了可以给向量的每个元素起名字,R当然也可以给矩阵元素的行和列都起名字,使用的函数是dimnames,由于对矩阵的行和列进行命名的时候需要用到列表,因此具体的代码等到后面学完列表再展示
数组
数组与矩阵非常类似,区别在于矩阵的维度只能是2,也即行和列,但是数组的维度可以大于2,也可以等于2,如果创建数组的时候使用的维度是2,那么此时的数组和矩阵没有任何区别。
创建数组需要的是数组的维度以及初始化数组的内容,创建数组使用的是函数array,其中dim参数在传入的时候通常要使用c函数拼接,比如

运行结果如图,我们创建了一个四行六列的数组,这与矩阵没有任何区别
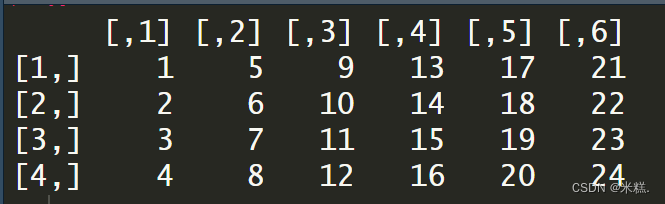
再来看看创建的时候给dim三个维度会发生什么,注意维度的乘积一定要和初始化内容的个数匹配,比如我们初始化的内容给了1到24,后面维度就是2*3*4=24。如

运行结果如图
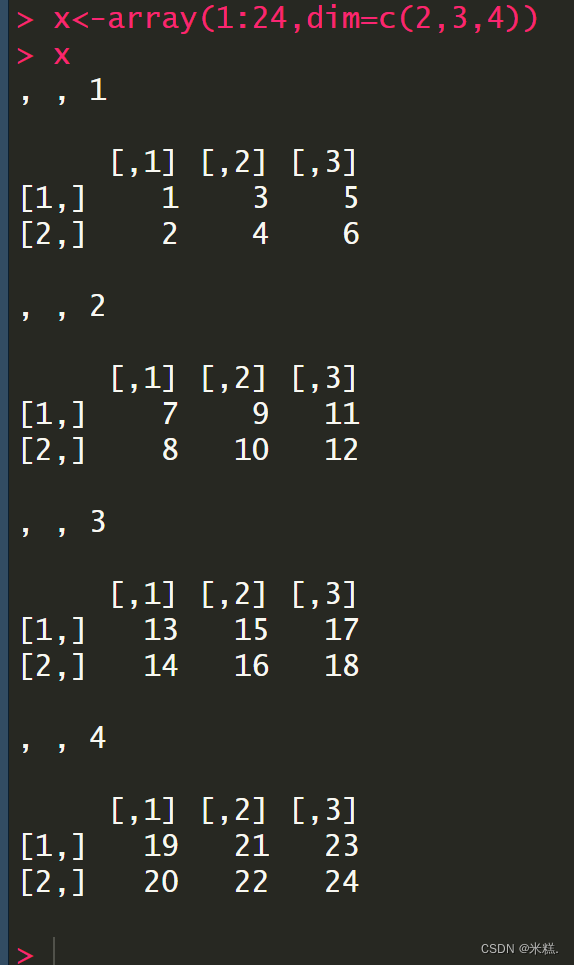
可以看到结果是两个逗号再加一个数,这个数代表的就是第三个维度,然后我们可以看到有四个矩阵,这表示第三个维度里面一共有四个元素,每个元素都是一个两行三列的矩阵。同时注意到我们赋值给的数据1到24,是先填充第三个维度的第一个元素也就是这个两行三列的矩阵,然后是第三个维度的第二个元素以此类推。
R中最常用的数据结构其实是向量,矩阵,数据框,对于数组应用的并不多,了解即可。
列表
列表与矩阵的区别就是矩阵中所有元素都必须是同一类型,而列表只需要每一列是同一类型即可,不同列之间可以是不同类型的数据,且每一列的元素个数不一定相同
创建列表使用的函数是list,如图

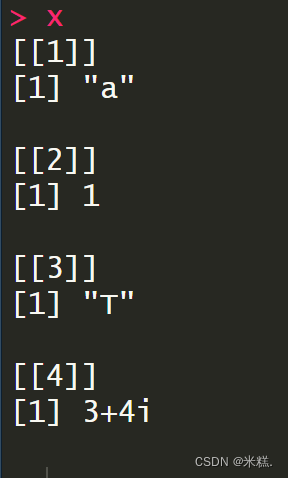
运行结果如图,发现结果有点复杂,有一个东西是两个中括号引起来的,还有一个东西是一个中括号引起来的。其中两个中括号引起来的表示这是列表中的第几个元素,一个中括号的是列表中元素的维度情况。不管列表有多复杂,他的元素个数只与逗号有关
列表中有四个元素,第一个元素的内容只有一个a,第二个元素的内容只有一个1
如果这样创建

列表中就有两个元素,第一个元素的内容是1 2 3,第二个元素的内容是a b c

再比如这样
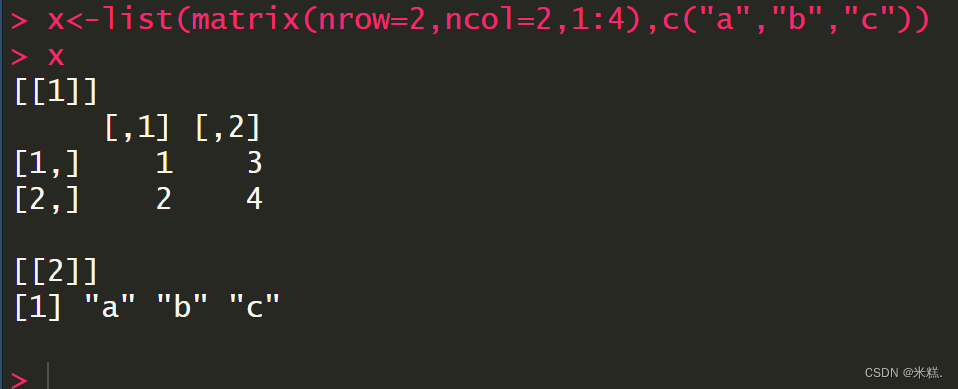
创建的列表仍然是两个元素,第一个元素的内容是一个两行两列的矩阵,第二个元素的内容是一个向量。
这种由两个中括号表示的虽然也是列表的第几个元素,但是看起来挺抽象的,我们其实可以再创建列表的时候给列表每个元素起个名字,比如
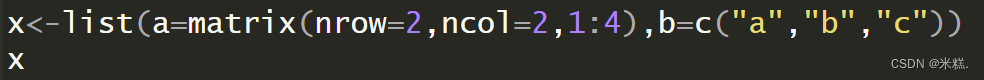
我们把第一个元素起名为a,第二个元素起名为b,运行结果如下

表示元素a是一个两行两列的矩阵,元素b是一个向量。这样可读性就好了很多。
发现没,其实可以把列表理解成一个进阶版的向量,他并不是一个高维的数据结构,而是一个一维的,但是他的每个元素的类型可以是任意维度的,比如向量,矩阵,数据框。
现在来填一下对矩阵的行和列进行命名的坑,对矩阵或者数组的行和列进行命名的函数是dimnames,如图

首先创建了一个列表,这个列表有两个元素,第一个元素是一个向量,内容是a b c,第二个元素也是一个向量,内容是d e,而对一个矩阵的行和列进行命名,也就是需要这么两个向量。运行结果如图

因子
因子是用来处理分类数据的,分类数据分为有序的和无序的。比如年级有大一大二大三,这就是有序的,再比如性别有男有女,他们无法比较大小,这就是无序的。可以把因子理解成整数型向量+标签,比如可以让1代表男性,2代表女性。但是因子肯定要优于整数向量,因为因子的可读性较好,这就好比C语言中的宏,或者枚举类型的好处。如果我们直接写成1,2可能过一段时间就忘记了这个1和2代表什么,但是如果我们写成因子类型,就可以一眼看出描述的是什么意思。因子这种数据结构是在以后做线性或非线性模型中经常要用到的。
因子类型的创建

如图,因子类型的创建使用的是factor函数,运行之后发现结果是一行向量再加一个levels,表示当前的因子包含两个水平,分别是female和male,levels是因子的特有属性。
如果我们在factor函数里面加入第二个参数levels,如图

发现运行结果如图

和不加入levels参数的区别就是levels的位置先后
如果我们想要对当前的因子有一个整体的认识,可以使用table函数
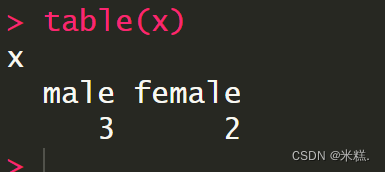
运行结果表示当前因子中有三个male两个female。
我们说levels是因子独有的属性,我们其实也可以对因子进行去属性,借助的函数是unclass函数,如图
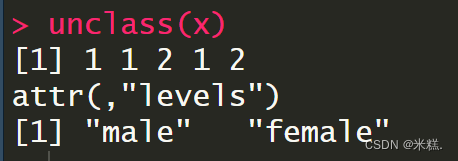
运行结果发现现在这个因子的元素变成了1 1 2 1 2,实际上就是1代表male,2代表female
缺失值NA
在R中,缺失值有两种表示形式,一种是NA,一种是NaN,其中NaN属于NA,一般NaN用于表示数字的缺失值,而NA的表示类型更广。如果要判断一个向量中是否存在缺失值,可以使用is.na()函数或者is.nan函数,返回值是TRUE或者FALSE,如图
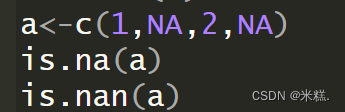
运行结果如图
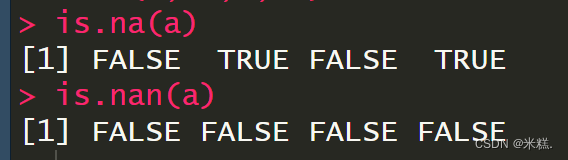
我们发现is.nan的结果居然全都是FALSE,这也印证了NA不属于NAN,如果我们对上面的a向量做一些改变,把缺失值写成NaN
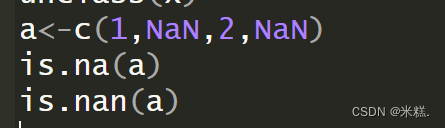
此时的运行结果为
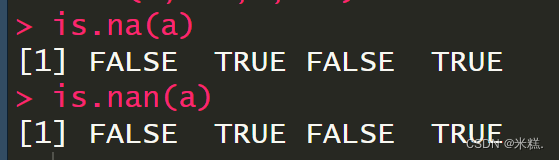
这就说明了NaN是属于NA的,而NA不属于NaN。
数据框
数据框通常用来存放表格数据,每一列的元素必须相同,不同列的元素可以不同。实际上数据框就是一种特殊的列表,数据框的每一列都是这个列表的一个元素,且因为数据框的每一列长度相同,所以这个列表的所有元素都是一个个长度相同的向量。这些向量的包含元素的类型不必相等。且这些向量包含元素的个数也就是每一列的长度
换句话说,数据框是一种每个元素都是相同长度向量的列表。
创建数据框使用的是函数data.frame,这个函数的参数就是每一列的内容,我们可以在创建的同时对每一列进行命名,如图

运行结果为
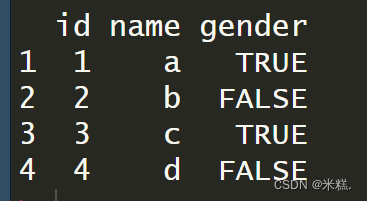
顺便提一下,如果不在创建数据框的同时进行命名,也是没有语法错误的,只不过创建出来的数据框是这样的
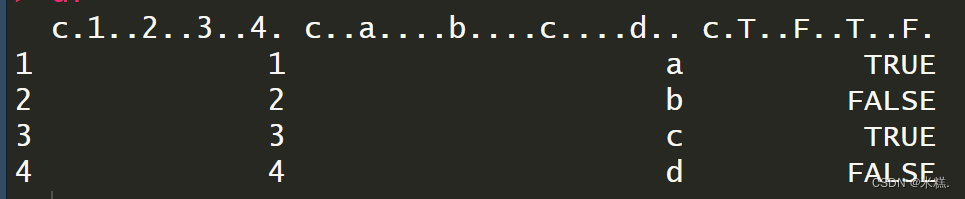
非常的难看,因此强烈建议再创建数据框的同时对每一列进行命名。
R的数据结构总结
R的对象类型有五种,分别是字符型,数值型,整数型,复数型,逻辑型
常用的数据结构有向量,矩阵,数组,列表,因子,数据框。其中后面几种数据结构都是基于向量的,比如向量+两个维度就构成了矩阵,加两个以上的维度就构成了数组,不同类型的向量可以构成列表,如果这些含有不同元素类型的向量的长度均相同,就构成了数据框,整数型向量加标签就是因子。
创建各种数据结构使用的函数:
创建向量:1.vector函数 2.使用冒号 3.使用c函数
创建矩阵:matrix函数
创建列表:list函数
创建因子:factor函数
创建数据框:data.frame函数